已經看過《Year End Report - ART - From Dalvik to ART》的讀者,可將此篇當成續篇來看;還未看過的讀者,建議可先看完前篇,再接續此篇的內容。
目前更新到2008 - 2018年,以下圖片來自不同年份的Google IO或Android Dev Summit。
Android自從一開始發展時,是將程式編譯成Dex檔,並執行在Dalvik VM之上。儘管Google一直嘗試在此架構上進行優化,始終有些限制讓優化的效果有限。於是Google在2014年的IO大會中,安排了一個session,公開發表了新的VM環境,ART(Android runtime),來取代Dalvik。
當然,任何開發都不可能一次到位,所以Google在之後幾年持續進行ART的優化,並於IO上發表。以下將會整合這幾年的內容,但不深入討論,目的是使讀者可以快速的理解ART。與時共進,此篇文章也會在有新更新時進行修正。
截至目前為止,ART主要從兩面向進行優化,來達到更好的執行成果:
- Compilation
- Garbage Collection
由於橫跨好幾個年份。以下將不同篇章來介紹這兩個面向的調整,作為系列的第一篇,將從編譯器開始。
Compilation
這部分又可以再細分成兩個面向:
- Compiled code
- Compiler
Compiled code
在歷年的talk中對於compiled code的優化著墨不多,不過不同於以往的Dalvik編譯器只針對迴圈、判斷式等此類屬於程式基礎架構的優化。ART也會針對abstract、interface等,只有OOP程式才會出現的程式碼進行優化。
當然Google不會止步於此,所以後續也有很多特殊的優化,詳細可以查看以下2017年IO的talk:
- Performance and Memory Improvements in Android Run Time (ART):可直接轉到最後一位講者,比較特別的部分是透過SIMD指令架構達到平行運算,提升影像處理的效率。
Compiler
JIT (Just in time)
在看ART做什麼改變前,先來回顧JIT是什麼。JIT是一種編譯器的技術,就是程式會在執行時,才會被即時編譯並執行。會導入JIT,是因為Dalvik需先透過Interpreter解析Dex code,中間過了一手,勢必會影響效率。在這不細談,有興趣可以直接參考以下兩個talk:
- Google I/O 2008 - Dalvik Virtual Machine Internals
- Google I/O 2010 - A JIT Compiler for Android’s Dalvik VM
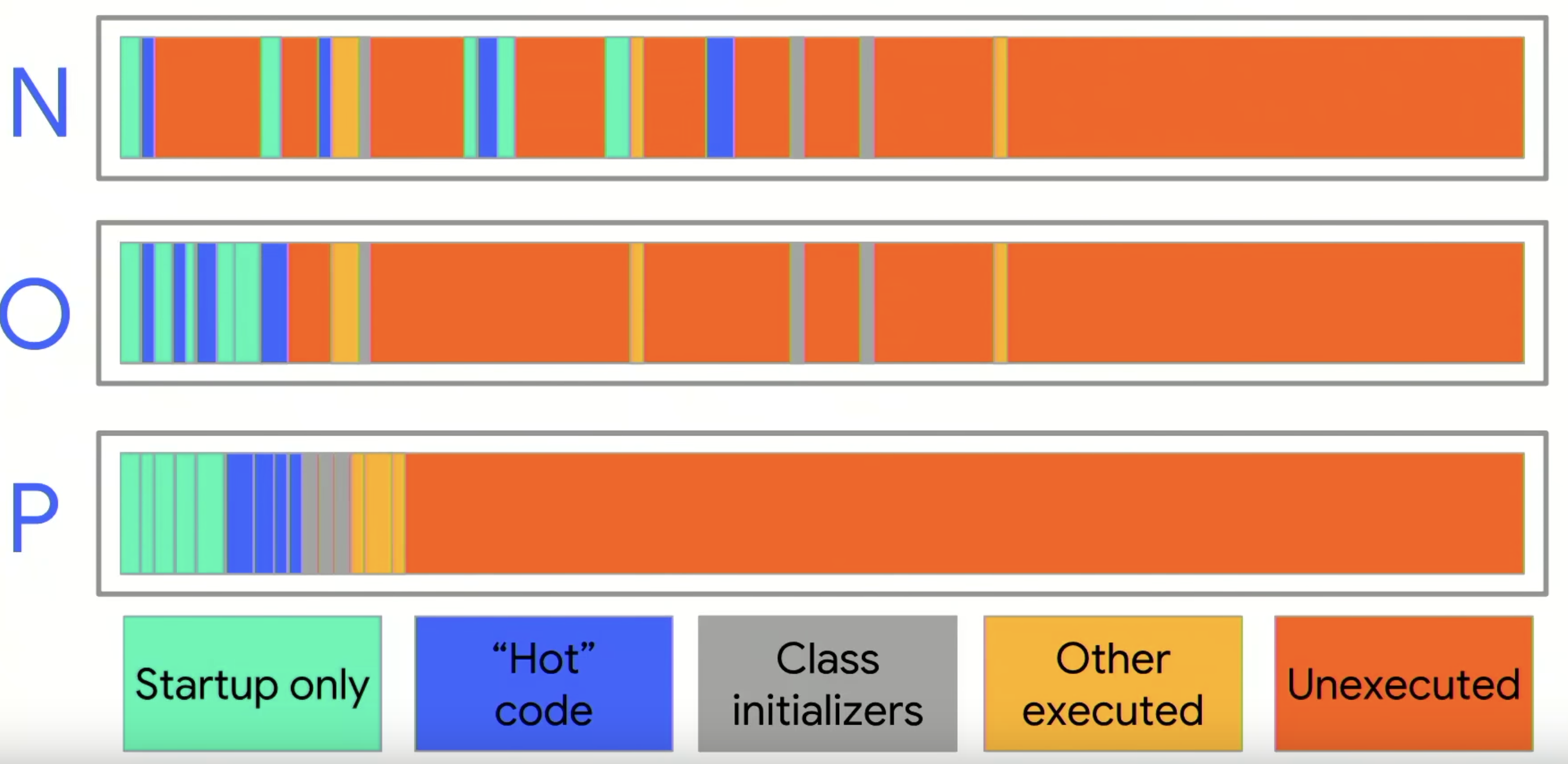
JIT有分兩種類型:Trace-based和Method-based,Google在Dalvik時期採用Trace-based,AOT時期改採Method-based。
Trace-based
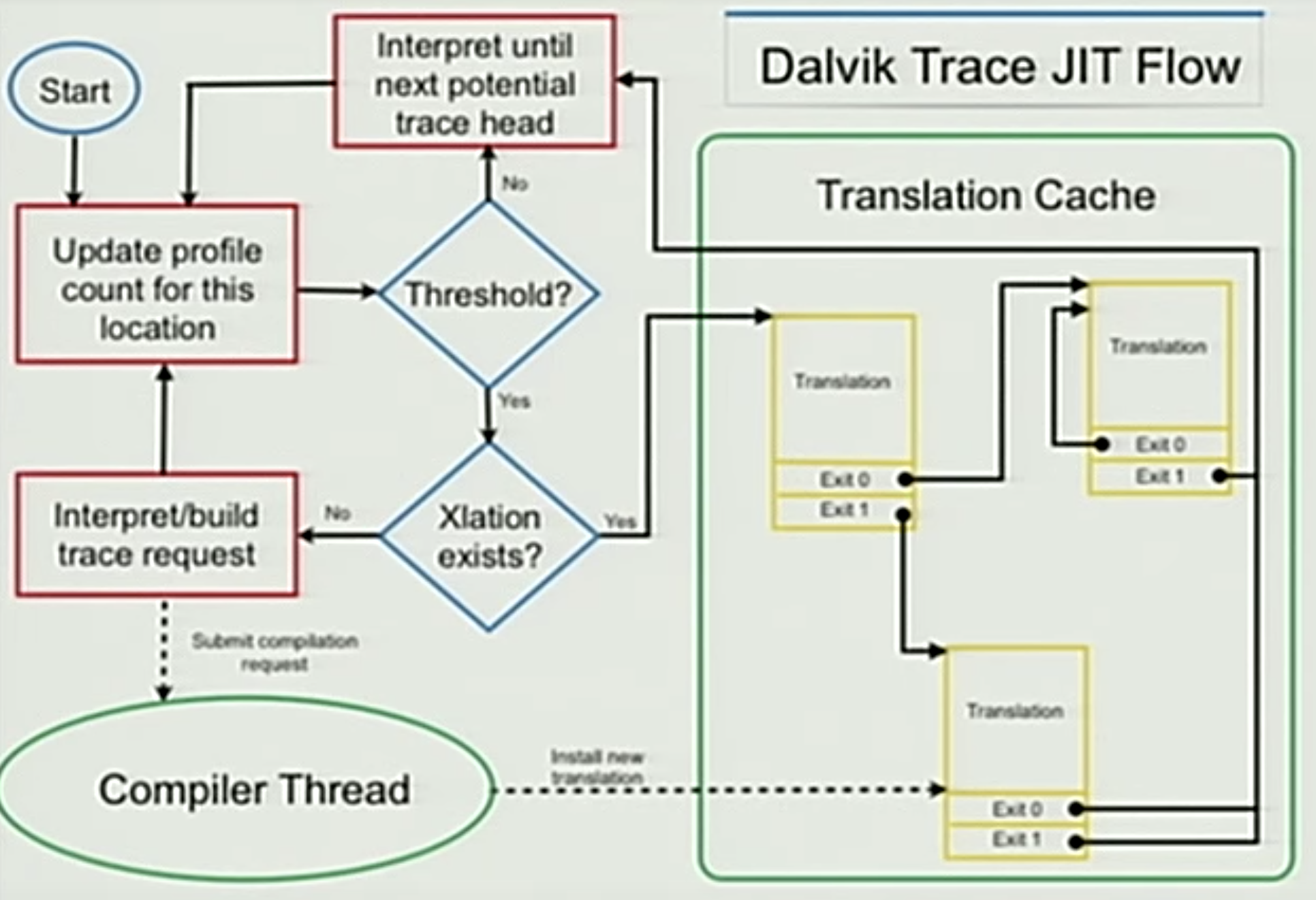
此種就如其名,是針對一連串的程式執行路徑,以下用最初執行的狀態開始,並按照步驟說明:
- Update profile count:當一段程式執行路徑的起點被執行時,JIT會紀錄次數。
- Threadhold:判斷執行次數決定是否值得被處理。JIT會透過給定的數值,將程式片段標成Hot或Cold。如果是Cold,則會直接透過Interpretor執行;如果是Hot則進入下一步驟。
- Xlation exists:判斷是否有編譯過。JIT會cache已經編譯過的程式片段,來提高整體效率。如果曾經有編譯過,則會拉出cache並執行;反之則送出編譯的需求,由系統決定何時進行編譯。
- Compiler Thread:編譯程式路徑成native machine code。
- Translation Cache:Cache編譯後的native machine code,供前一個步驟搜尋取用。而因為Trace-based JIT編譯的是一段操作路徑,所以編譯後的Trace有機會頭尾相接;反之,則回到Interpreter。
Google使用Trace-based JIT的原因如下圖:
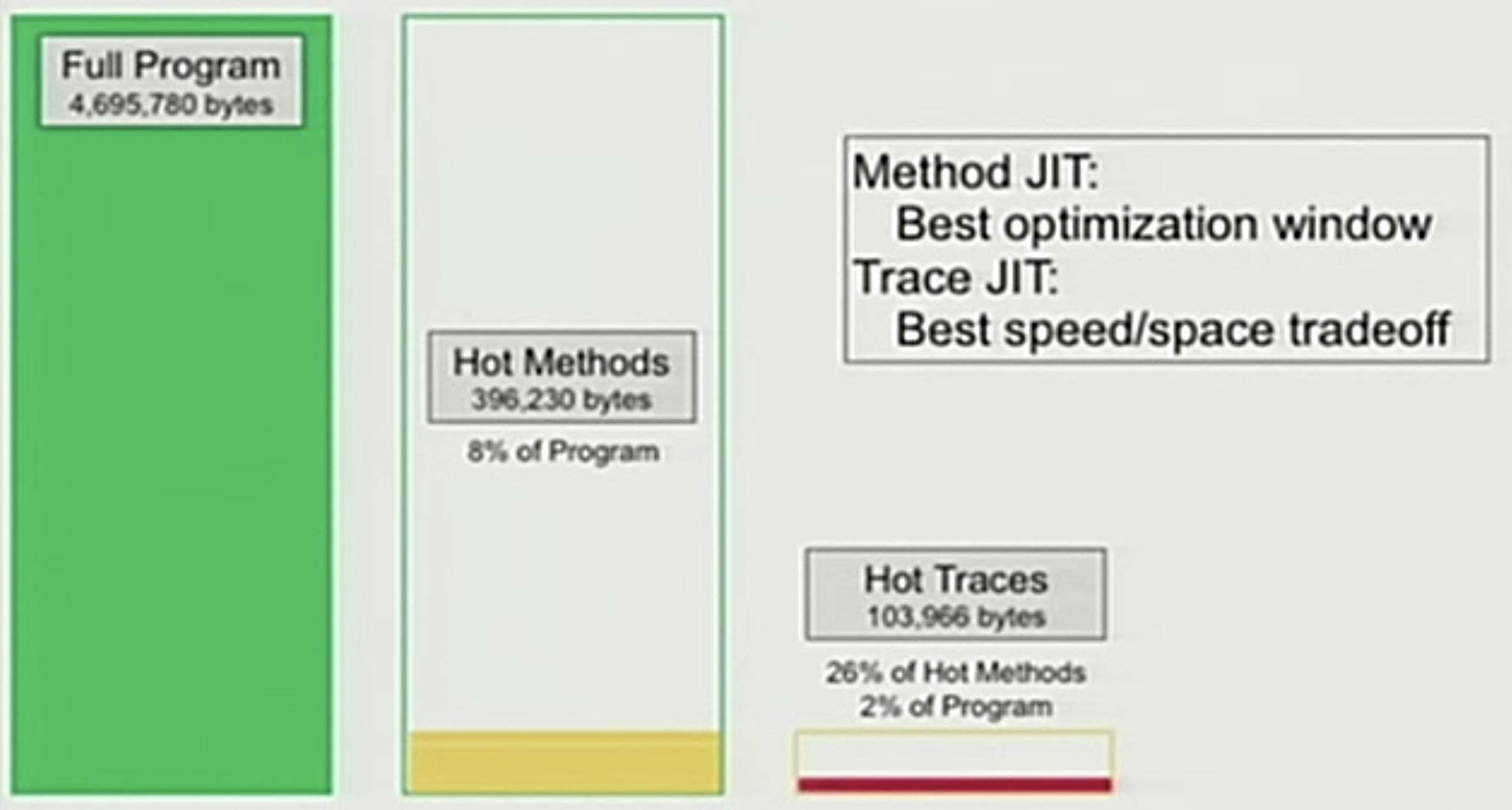
根據測試統計,雖然只有8%的函示已經很少了,但這些函示內又只有26%會被執行,放到總體更是只有2%。所以相較起來Trace-based可以更精準的定位到會被執行的程式片段。
可以預期的是,長期使用後,所有常執行的Trace,一定都會變成Hot,就都會使用cache執行,達到效率的最大化。
雖然效能提升了,可是JIT有幾個缺點如下:
- JIT在每個application都有一個私有空間做cache,所以kernel無法部分回收,當記憶體不足時,只能直接停止application才能取回記憶體。
- 程式需要運作一段時間後,才可以處理到所有最常被執行的路徑。且cache會在application清除後被回收,如此在最糟的情況,JIT需要不斷的重複編譯,造成電源的消耗。
這些缺點是JIT的硬傷,尤其是電源消耗和記憶體問題,所以在ART取代Dalvik後,Google也順勢以AOT取代JIT。
AOT (Ahead of time)
與JIT一樣,AOT也是一種編譯器的技術,不同的是編譯的時機,AOT是在執行前就進行完整編譯。
編譯後的native machine code會以Oat檔存於硬碟空間,Oat同時也是ELF檔,ART會直接存取內容執行。由於ART是基於Linux kernel所設計的VM,可對執行緒和記憶體提供更有效的控制,也才有新的GC設計。
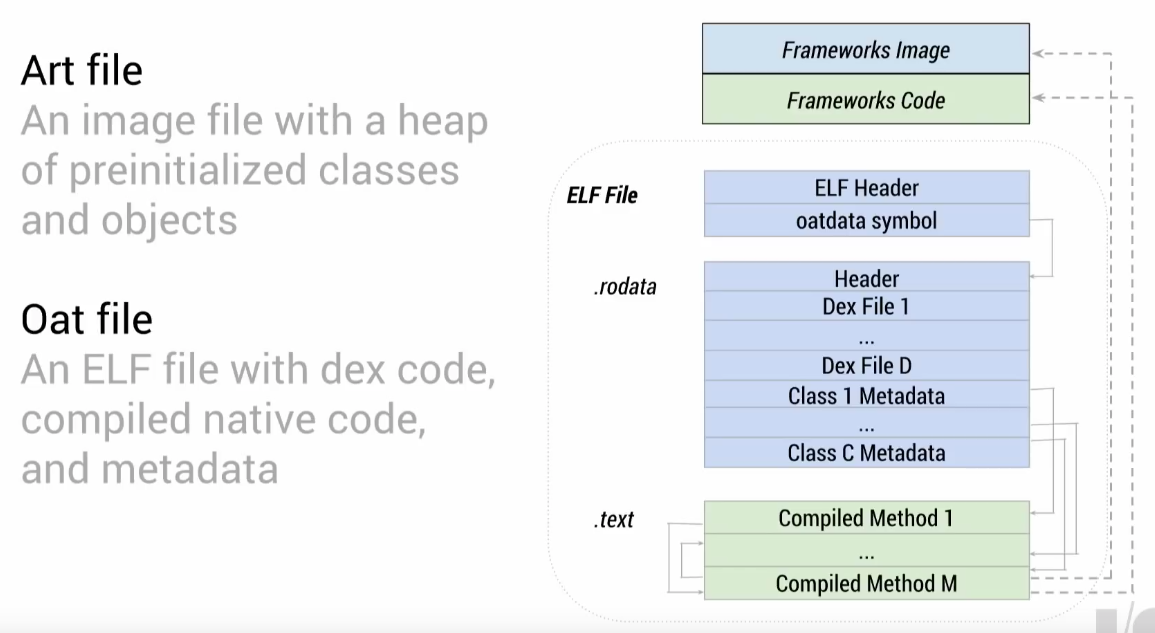
Oat內含編譯過的native machine code和Dex檔的內容,並保留Dex透過連結來連結各種類別、函示的方式。另外,為了方便debug時提供有效的訊息,Oat內也會留著原本的Dex檔。
另外,安裝時就完成了編譯,就不需要重複編譯,降低電源消耗。
但AOT也有缺點,以下兩點就是硬傷:
- 編譯後的native machine code佔用空間龐大,但依照之前JIT的測試統計,可知真正有執行到的部分很少。
AOT屬於系統層面的轉換,所以有重大更新如OTA,就會重新編譯所有已安裝的APP,以求套用系統更新帶來的修正或優化。這樣的操作是非常花時間的,因此有一段時間,Android使用者會很常看到以下畫面:
一開始,考量到後續效益,Google認為這樣的代價是合理的,畢竟系統更新並不會常常發生。直到2015年Android Security發了公告,決定將OTA更新頻率拉高到每月一次,以求更快速的套用安全更新,則如此的更新效率就無法讓人接受了。
不論如何,不論用JIT或是AOT,都有一些根本的問題不易解決,於是2016年,Google將JIT與AOT合併。
AOT + JIT
這兩者混合後,就順利解決AOT問題:
- 不在安裝時編譯,讓編譯在不同時機執行,就不需要更新的等待畫面,也就可以應付高頻率的系統更新。
- 只編譯較常執行到的部分,也降低編譯後的硬碟空間消耗,這連帶的也是會降低記憶體的使用。
由於主體還是AOT,所以即使加入了JIT的概念,AOT在效能以及電源損耗上的優點也依然保留。
Main flow
主要的流程和前面提到的JIT大致類似:
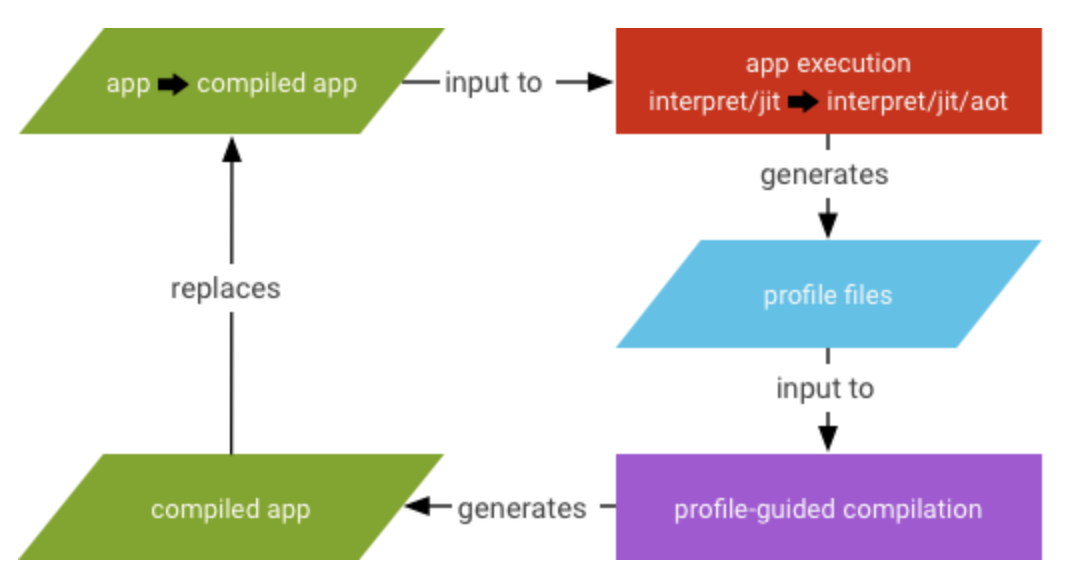
- 一開始沒有任何程式被編譯過,所以直接透過ART執行,並先用JIT進行編譯優化。與此同時,JIT會將其紀錄的內容,導出至Profile。
- 導出的Profile會在手機進入待機且充電的狀態下,被傳給JIT Daemon,來進行編譯的動作。
- 如前面初次講到AOT時有提過,編譯後的native machine code會存成Oat檔,取代原本的Dex檔。
Profile
AOT的JIT使用的Profile會存放於硬碟空間,裡面有以下三種紀錄:
Hot method:如同原本JIT就有的功能,會紀錄執行頻率較高的函示。
Classes at startup:紀錄在application啟動時會用到的類別,這是為了在此版導入的Application image。當Application開啟時,需要透過ClassLoader讀取很多不同的類別來進行初始化的動作,這些讀取和初始化類別的動作都需要時間。
Google解法是將這過程直接搬到編譯時期,讓Application image裡面存的是已經準備好的類別物件,Application啟動時只要將image讀取進來就可直接使用。
Loaded by other apps:紀錄是否可從其他app執行。此會影響JIT Daemon編譯的決策。
雖然Profile需要時間建立,但使用者大多的步驟勢必是重複的,可推斷不同使用者的Profile相似度其實不低。因此在2018年,Google提出了Cloud Profile:
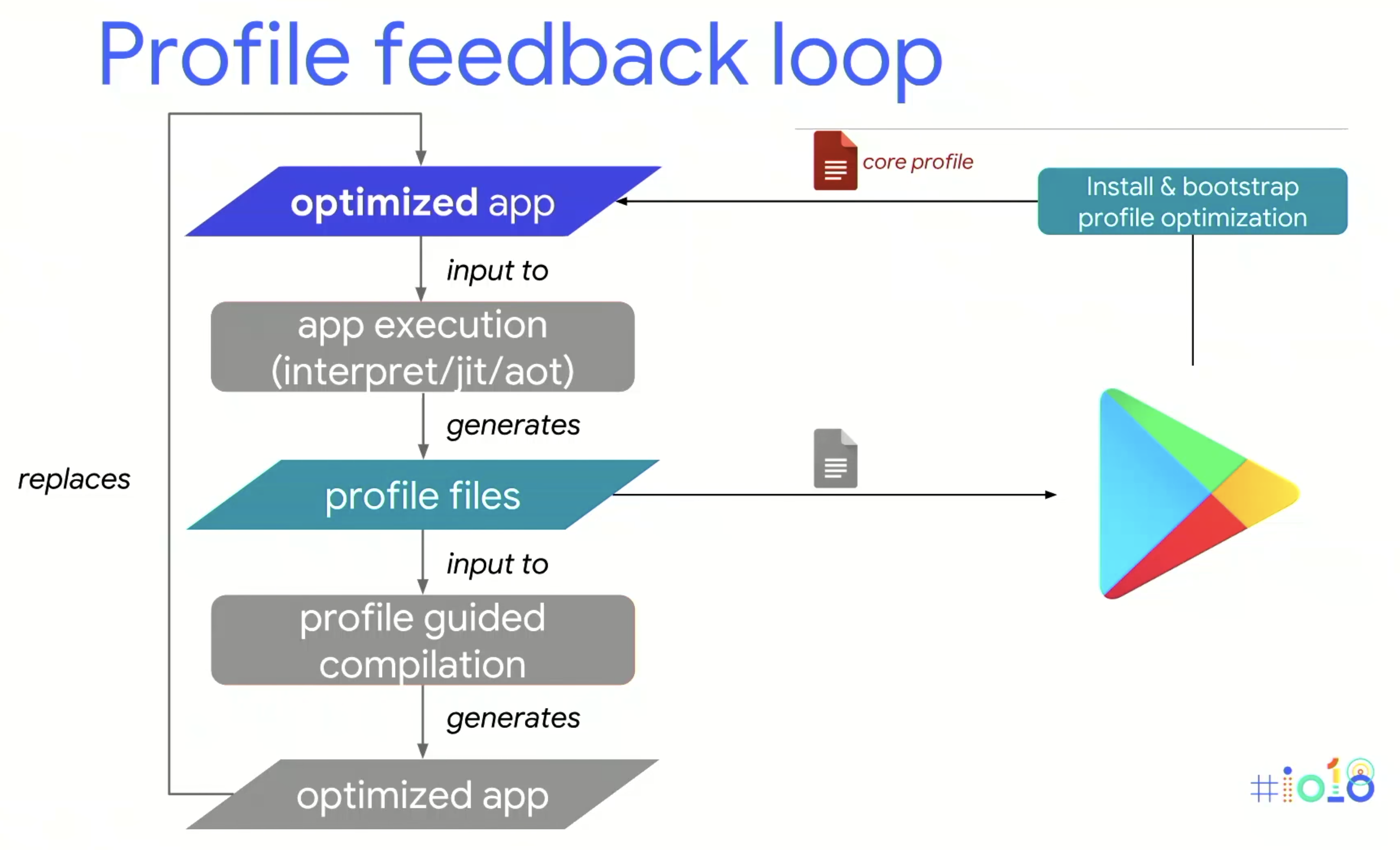
目的是讓APP,尤其是在alpha或beta階段時,可以上傳Profile,並由Google產生出一個優化後的Profile。則開發者就不止在開發者介面可以查看Profile,使用者在下載時也可以直接得到現成的Profile進行優化,就不需要歷經長時間使用來建立可靠的Profile。
JIT Daemon
當手機啟動時,JIT Daemon會被系統啟動,為長時間運作的service。每一天JIT Daemon都會掃過所有的app,決定是否要進行編譯。另外,前面也有提到,在手機進入待機且充電的情況下,這個service也會被啟動。
其判定是否要編譯的流程如下:
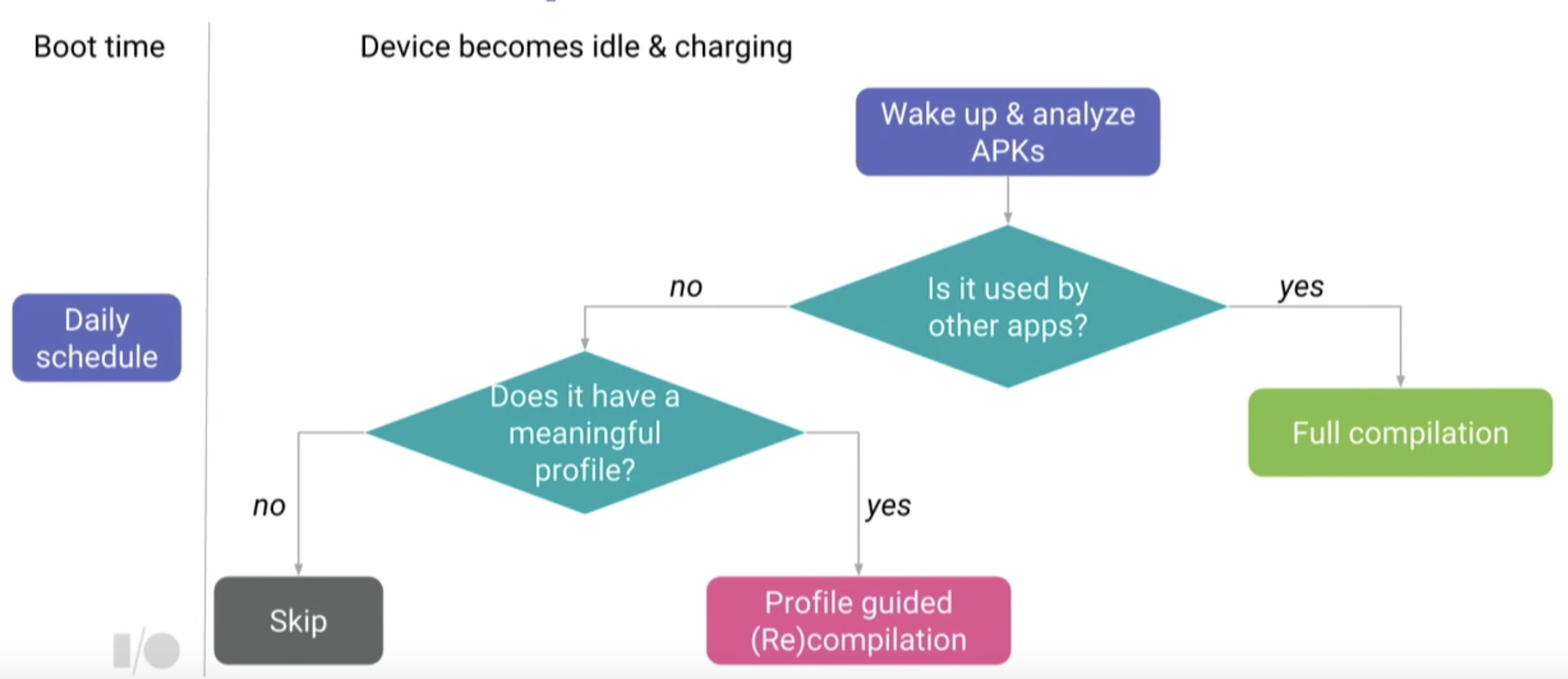
- 是否有被其他app使用,有的話則認為是shared library,整個都會被編譯,如此等於同步優化到其他有使用此library的app。
- 是否有meaningful Profile,有的話就會編譯Profile內記錄的部分。這邊meaningful意思是,如果Profile所記錄的資料不夠多,那做優化的效益就不大。
雖說混合後整體在各方面都提升許多,但仍然有優化的空間,如Startup time、記憶體和儲存空間的使用。這些實際上都與Dex檔的使用或是大小有關,也因此Google也做了以下優化:
APK extraction and Verification
在初次混合AOT和JIT時,因為沒有進行編譯,所以Application啟動時依然要先從APK內取出Dex檔,並進行驗證,於是啟動時間就變得比只有AOT時還差:

由於這是必要的過程,但又不能讓其佔據整個啟動的時間,所以Google將其依照原本AOT的方式,把這解開APK和驗證兩步驟移至安裝階段,但不進行編譯:
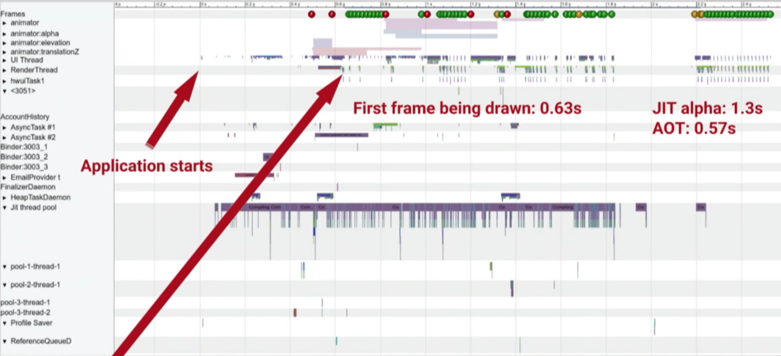
如此就又回到只有AOT的速度,維持住效率。也因為做了這樣的改動,接下來的優化才得以順利套用。要注意的是,此優化只是將這兩個步驟移出,但JIT編譯時依然得進行解壓並驗證,也才有Vdex產生。
Vdex
2016年的Nougat,Google為了解決每次在編譯時,都要歷經APK extraction和Verification的過程,於是乾脆將解壓後的Dex檔,和驗證資料打包成一個新的Vdex檔:
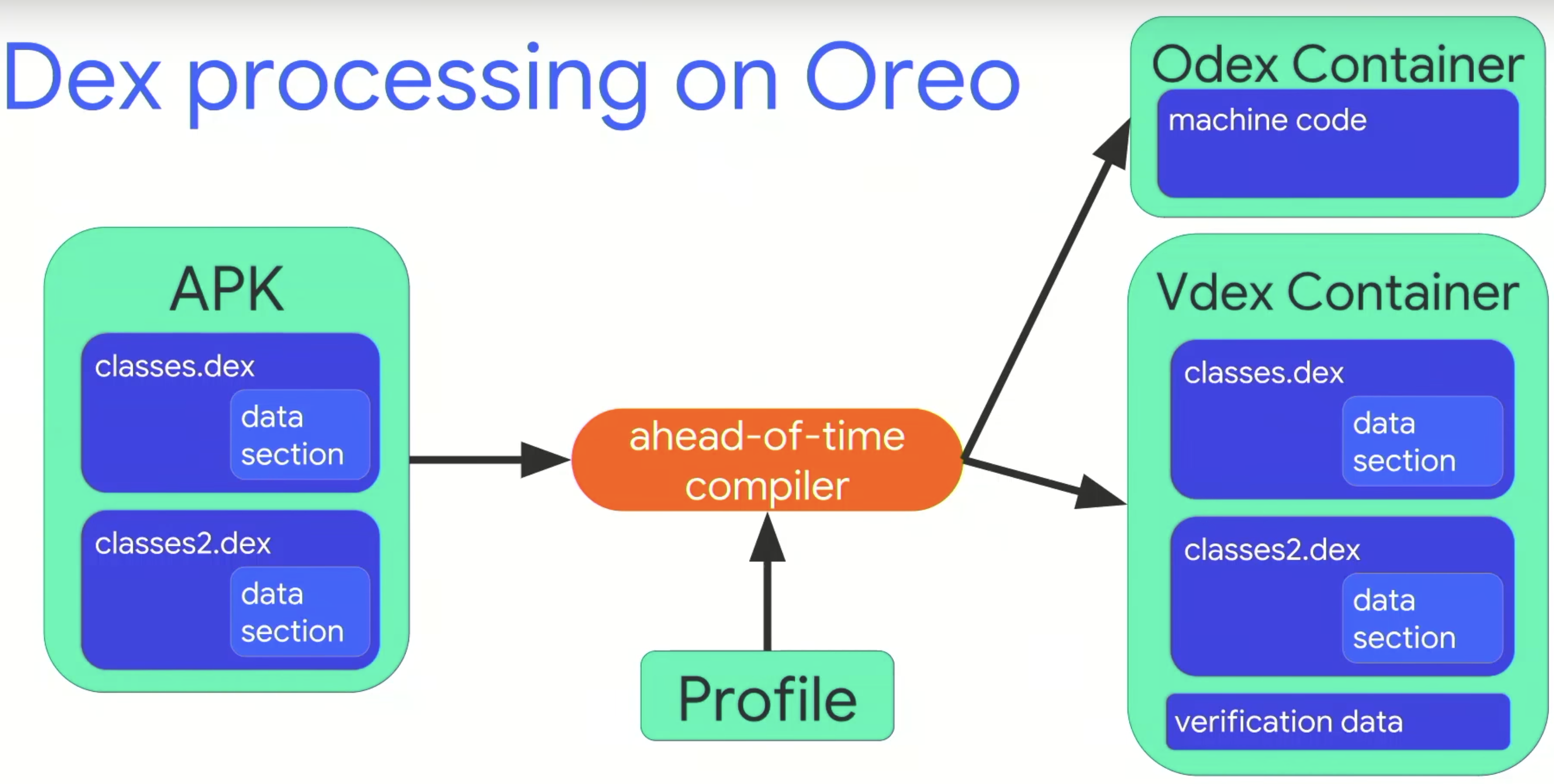
但這個缺點是會需要更大的硬碟空間,因為是在兩個地方各存編譯前和編譯後的版本。不過Google也有提供參數,ART_ENABLE_VDEX,這可以主動關閉此功能(預設開啟)。詳情可以看此commit log和官方文件。
Profile-guide Dex layout
與2017同年,除了Vdex以外,Google也同時在編譯過程中加了一個優化,也即是透過Profile所記錄的內容,來進行Dex檔內容的位置調整:
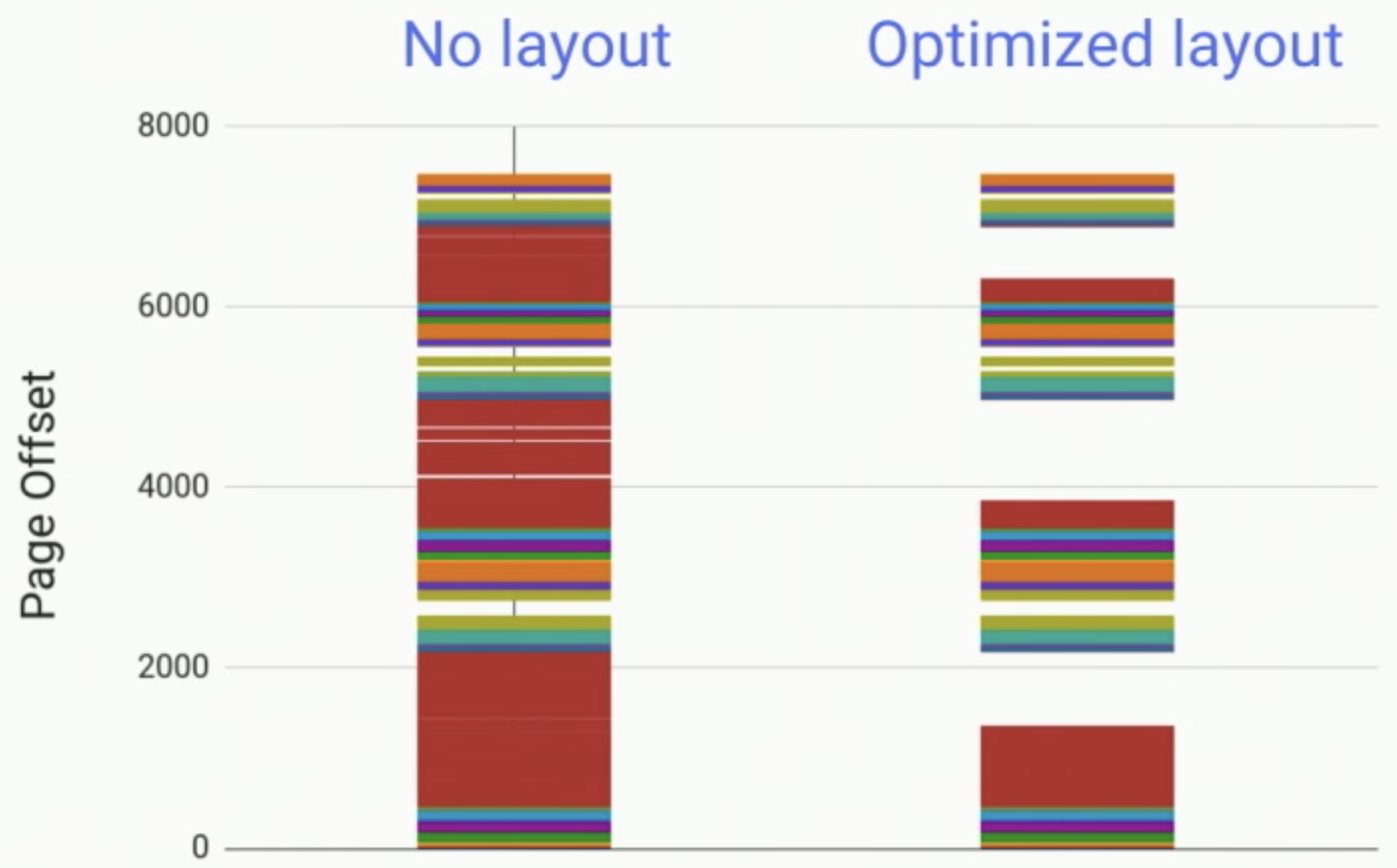
將Hot或是Cold相關的互相集中,這樣在讀取Dex檔時,就可以直接取出重要且連續的片段,而不會在讀取需要的部分時,也將不需要的部分讀出。
不過就算已經相關的部分集中,在圖上看依然是很雜亂。所以2018年,搭配更完善的Profile,Google進一步將內容依照類型完全集中:
如此當Application完成startup的過程,可以直接回收一整段的記憶體,而不是留下零散的空白。
-
雖然已經使用Vdex來打包預先解壓並驗證過的Dex,也用Profile重新分布Dex內的資料,但Dex依然有改善空間:
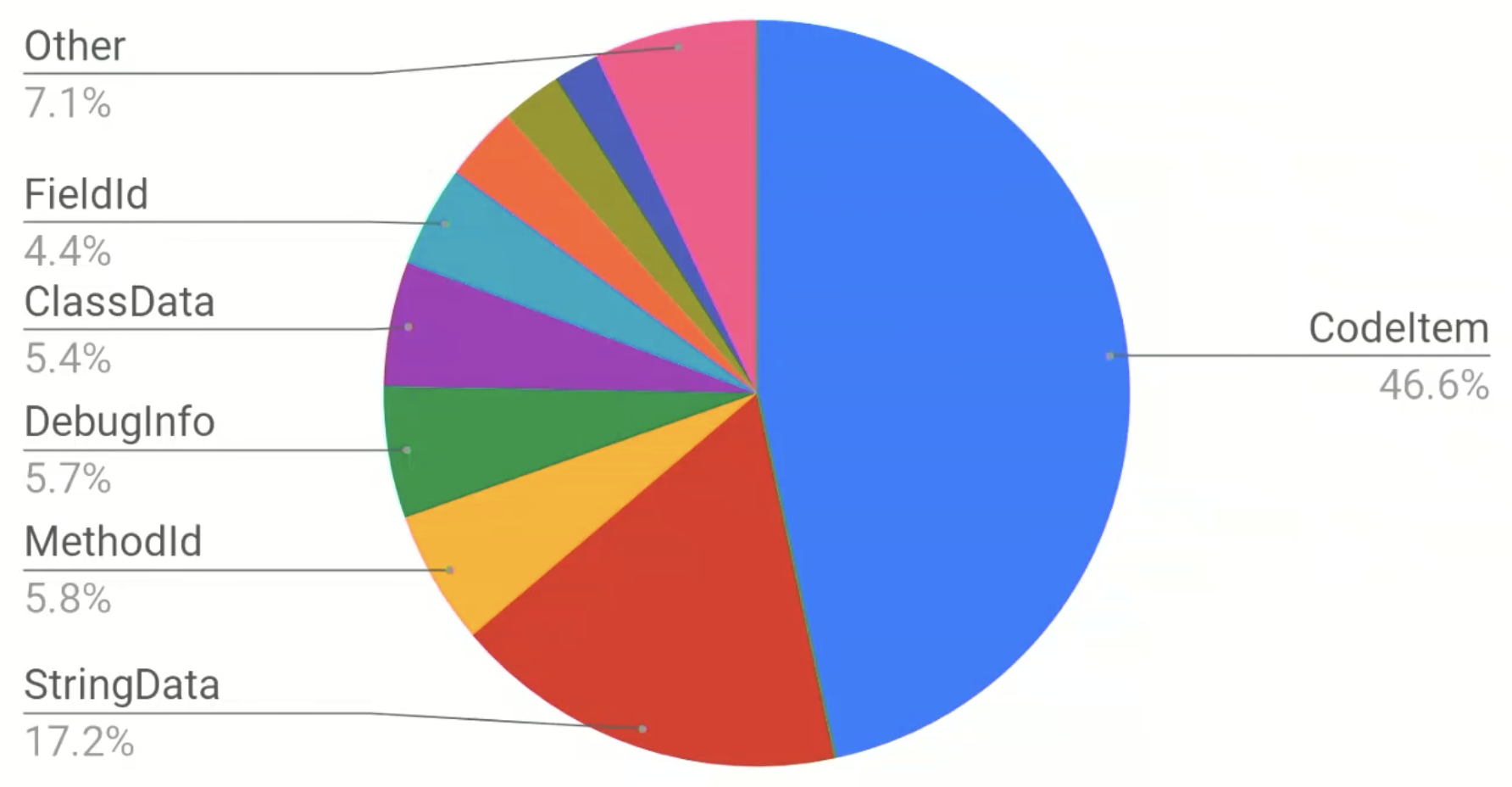
2018年,Google提出CompactDex來做出以下兩個主要的優化:
Deduplicate data section
因為Dex的限制,所以一個專案會被切成多個Dex。而Dex之間可能會有共同都有引用到的data,如StringData,因此每個Dex檔皆有保留相同的data section:
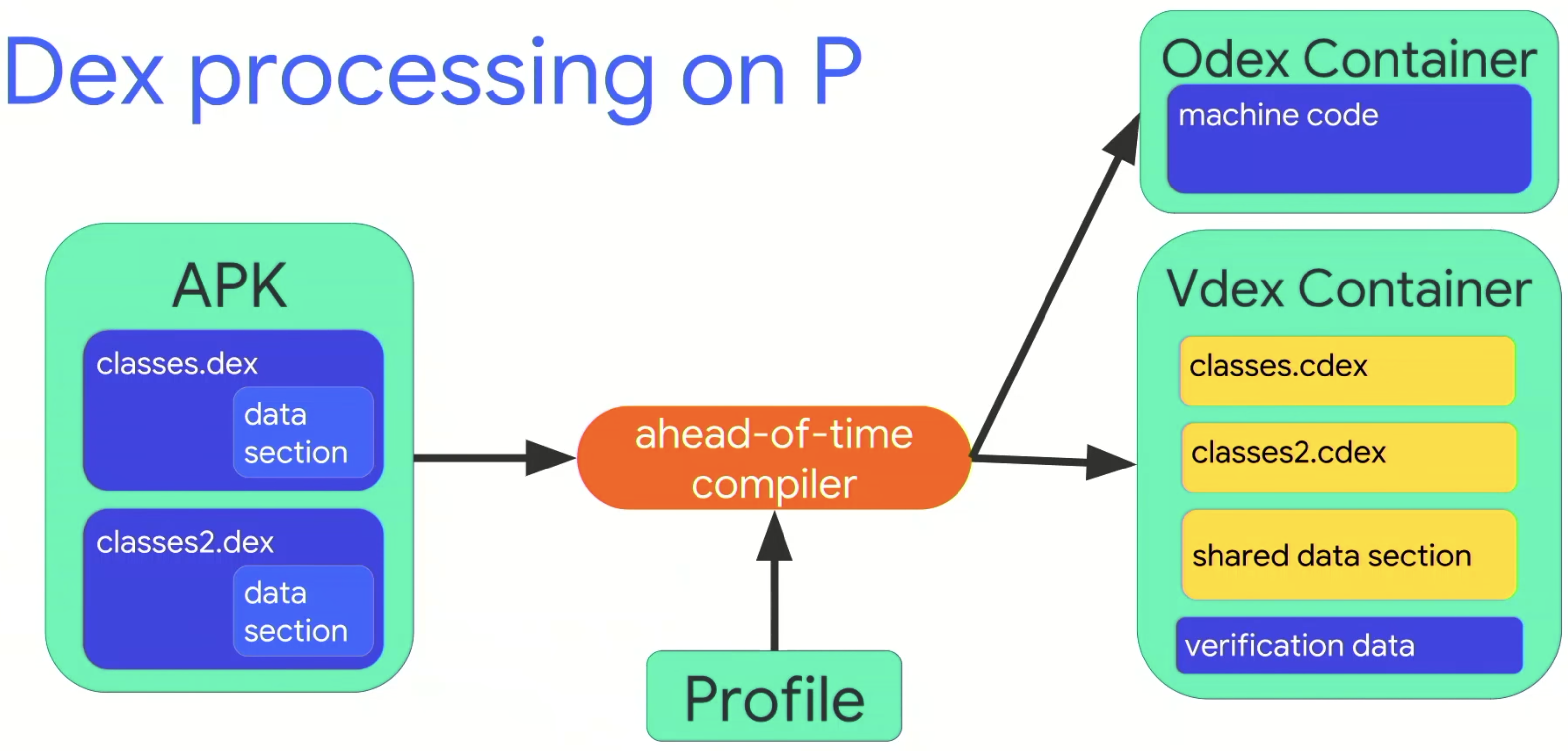
CompactDex重新規劃出一個shared data section,用於存放共用data。這樣調整不只針對StringData,其他部分有共用也會處理,只是StringData因為佔的空間最大,所以帶來的效益最大。
Shrink header of code item
Code item在Dex中代表一個Java函示,根據官方文件,原本其header會有16 bytes,而CompactDex做了以下轉換:
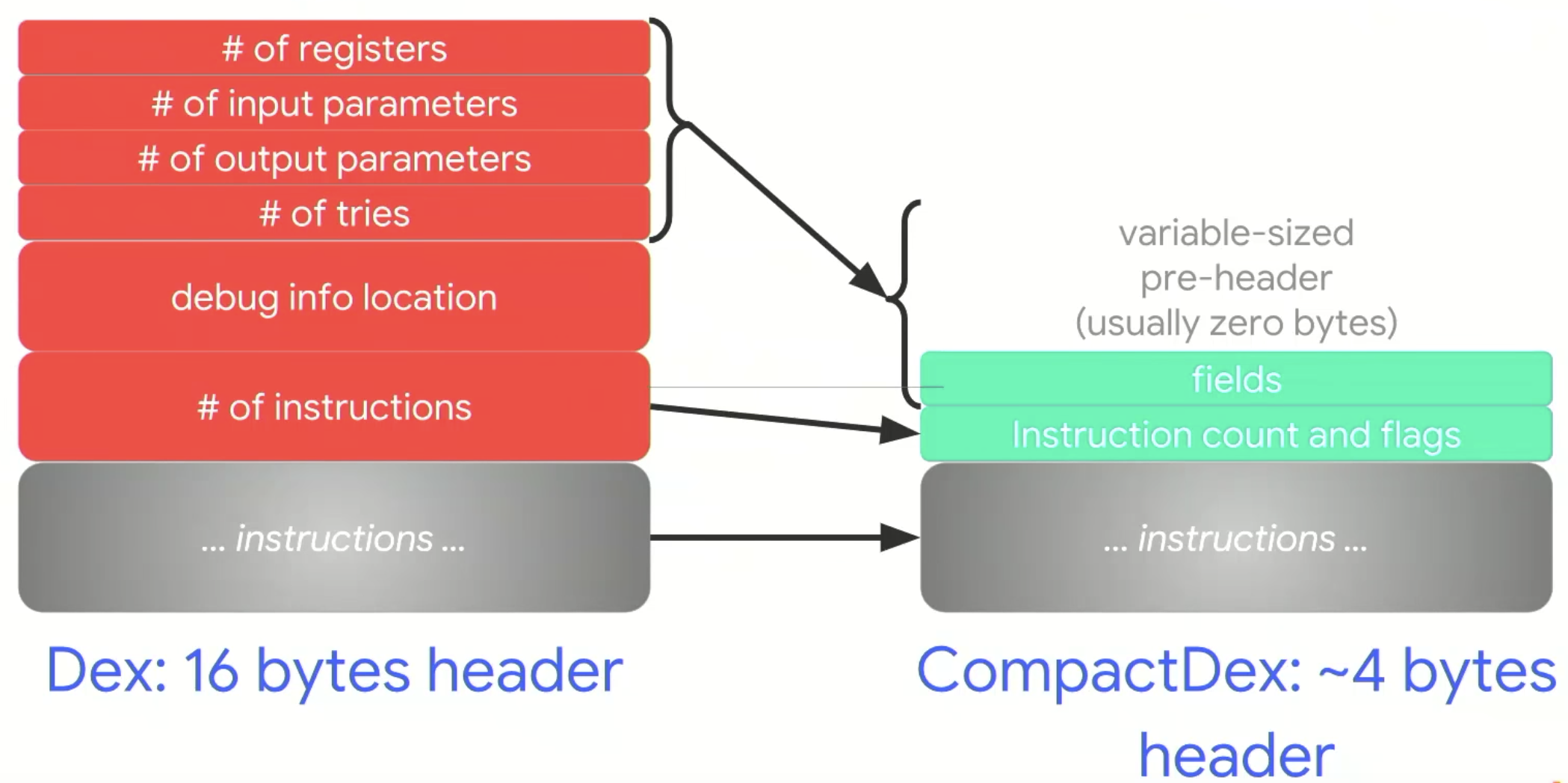
Register、input、output和tries:從ushort (2 bytes)縮為4 bits,並預留空間擴充,因為debug info被獨立出去,所以最高可達12 bytes。所以就從固定8 bytes,變成至少2 bytes。
Instructions:從uint (4 bytes)縮為2 bytes,其中細分11 bits做原本用途,5 bits為ART專用的flag。
Summary
以上就是截至2018年,Google在AOT上進行的一些優化。混合JIT和AOT的版本似乎已經接近完美,但這其實是建立在硬體的進步上,以上用到的Vdex或是cache,都是以空間換時間,這也許會是Google在明年之後繼續努力的方向。
接著下一篇,將繼續來看到這幾年內,Google在Garbage Collection上做了哪些優化。